Gemma 4 發布後,開放模型市場正在往哪裡走?
Gemma 4 讓開放模型競爭從參數規模,進一步轉向本地部署、多模態能力、授權條件與 agent 工具鏈整合。

目錄展開
Google DeepMind 於 2026 年 4 月 2 日發布了最新的開放權重模型系列 Gemma 4。如果只看表面,這像是一次單純的規模升級;但我認為更值得注意的是,Google 正在把 Gemma 從「可本地部署的開放模型」進一步推向「可直接拿來做多模態與 agent 工作流」的產品定位。
這個方向不只關乎模型本身,也反映出開放模型市場正在進一步分化。接下來的競爭,未必只是誰的參數更大,而是誰能在本地硬體、開放授權、多模態能力與開發者生態之間找到更實用的平衡。
Gemma 4 這次帶來了什麼?
根據 Google 官方資訊,Gemma 4 這次釋出了四個主要尺寸:
E2BE4B26B MoE31B Dense
這幾個型號對應的不是單一場景,而是從邊緣裝置、手機、單卡工作站到較高階本地部署的不同需求。這也讓 Gemma 4 的定位變得很清楚:它不是只想當雲端上的大型模型替代品,而是希望成為能夠跨裝置運行的開放模型家族。
官方目前強調的重點包括:
- 支援多模態輸入,包含影像與影片。
E2B、E4B額外支援原生音訊輸入。- 支援 function calling、結構化 JSON 輸出與 system instructions,方便接入工具鏈與 agent 工作流。
- 大模型最高支援
256Kcontext,小模型支援128Kcontext。 - 採用
Apache 2.0授權,商用與部署條件相對友善。 - 官方表示模型原生訓練覆蓋
140+種語言。
其中我認為很重要的一點,是這次改採 Apache 2.0。這不代表開發者從此完全沒有法律或合規責任,但就授權層面來看,商用、改作、再散布與自建部署的摩擦,確實比許多附帶額外限制的模型更低。對開發者來說,這意味著採用門檻又少了一層。
如果從產品策略來看,Gemma 4 的重點不是把所有敘事都押在「最強」,而是試圖把「可部署性」與「可用性」一起往前推。我認為這對開放模型的實際採用,比單一跑分名次更有意義。
Google 官方圖表
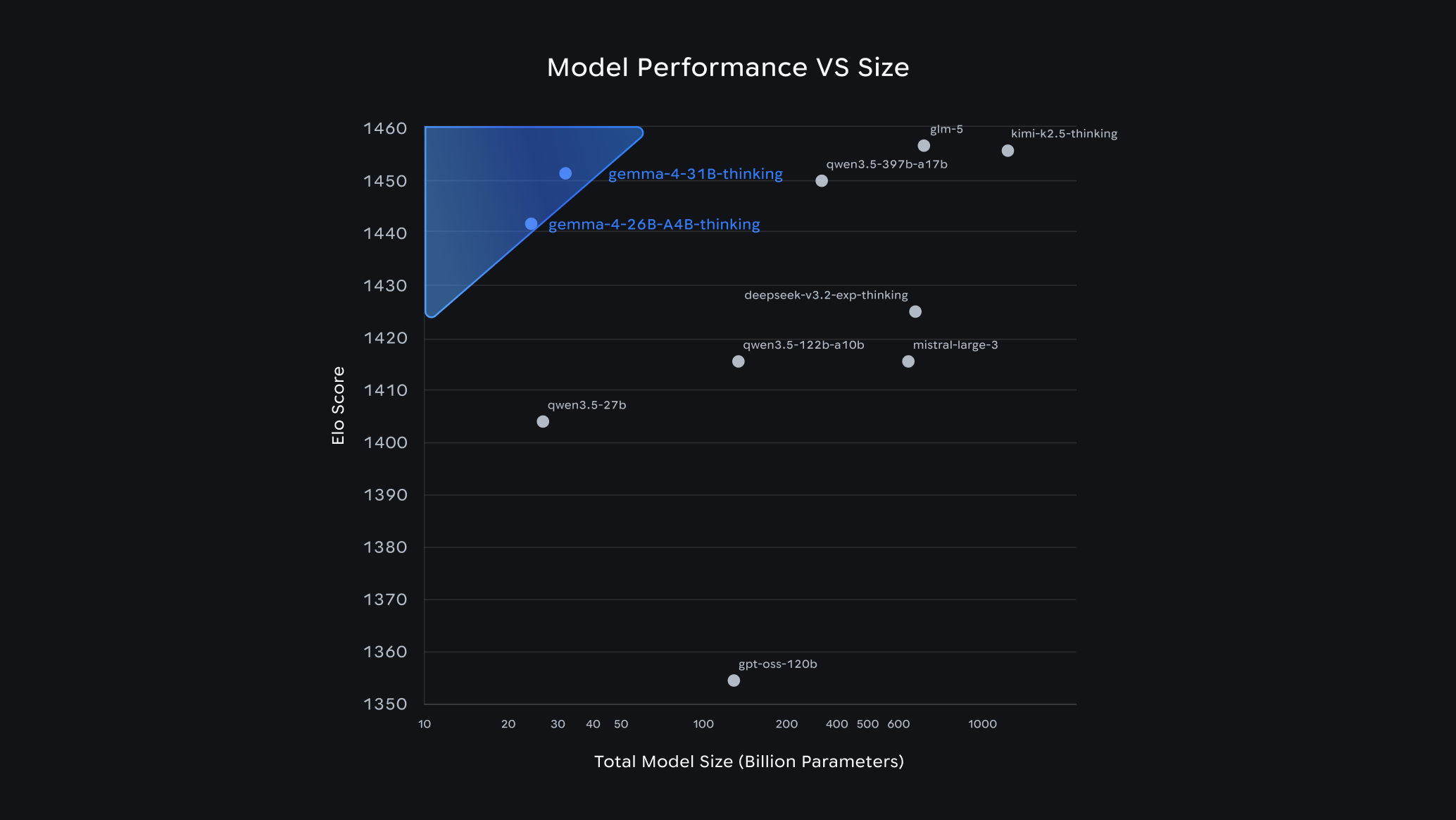
圖 1:Google 在 Gemma 4 官方部落格中公布的評估圖表。來源:Google 官方部落格。
這次更新值得注意的,不只是模型本身
Gemma 4 的價值,一部分來自模型能力,另一部分來自它背後的生態系安排。Google 這次明確把它放進一個比較完整的開發與推論路徑裡,包括 Hugging Face、Kaggle、Ollama,以及多種常見的本地推論框架與硬體平台支援。
這表示 Gemma 4 並不是一個只有官方 demo 才跑得起來的模型,而是被設計成可以進入開發者日常工具鏈的開放模型。對很多想在本地環境做原型、做內部部署、或做垂直領域微調的人來說,這比單純的發布消息更重要。
我的觀點:好消息不是只有一家變強
我自己更在意的,其實不是誰在某一份排行榜上多贏幾分,而是同一個可本地部署的級距,現在開始有更多成熟選項可以選。
以 Qwen 系列為例,這個參數帶近年在社群裡持續活躍,對很多個人硬體來說也剛好是甜蜜點:能力已經足夠進入實用區間,但又不像更大尺寸模型那樣,對顯存、記憶體與推論成本提出過高要求。
從這個角度看,Gemma 4 的發布不是要把其他開放模型壓下去,而是讓這個級距的競爭更健康。對開發者而言,有更多同級距、不同取向的模型可以選,本來就是好事。有人重視中文與社群生態,有人重視 Google 生態整合、授權條件,或更完整的多模態輸入路線;能夠依照場景選模型,遠比只剩下一個「標準答案」更有價值。
我樂見其成。
結語
Gemma 4 值得關注,不是因為它可以用一句話被定義成「全面勝出」,而是因為它讓開放模型市場又往前走了一步。它把多模態、agent 工作流、本地部署與開放授權整合成一個更完整的產品敘事,也讓開發者在同一個實用參數帶上有了更多選擇。
如果你在意的是能不能真正落地、能不能在自己的硬體上跑、能不能接進既有工具鏈,那 Gemma 4 這次發布的意義,可能比任何一張跑分表都更大。至少在我看來,這次更新最重要的訊號,不是哪一家把誰打下去,而是開放模型這條路正在變得更成熟,也更接近真正可用。
參考資料
- Google 官方部落格:https://blog.google/innovation-and-ai/technology/developers-tools/gemma-4/
- Google AI for Developers,Gemma 4 model card:https://ai.google.dev/gemma/docs/core/model_card_4
相關文章
Codex Mac App 大改版:從寫程式的 AI,進化成會用電腦的 AI
整理 Codex Mac App 的 Computer Use、內建瀏覽器、圖片生成、Memory 與 Automations 更新,並記錄實際使用 Zen 瀏覽器檢視網站的測試心得。
Claude Cowork 實測:Pro 訂閱夠用嗎?整理文章草稿為例
實測 Claude Cowork 在整理部落格草稿、排程與 Dispatch 等場景的體驗,並觀察 Pro 方案的用量是否足以支撐日常使用。
AI 開始會用滑鼠,但更重要的是開始會選工具
解析 Claude/Cowork 與 OpenClaw 的本質差異:重點不在於 GUI 操作,而是「連接器、瀏覽器、螢幕操作」的三層執行路徑優先權。